Project Objective
10 Academy is the client. Recognizing the value of large data sets for speech-to-text data sets, seeing the opportunity that there are many text corpuses for the Amharic language, this project tries to build a data engineering pipeline that allows recording millions of Amharic speakers reading digital texts on web platforms. There are a number of large text corpora we will use, but for the purpose of testing the backend development, we will use the data provided in this dataset.
Tools Used
The following platforms and tools were used for the project:
Apache Kafka
A popular messaging platform based on the pub-sub mechanism. It is a distributed, fault-tolerant system with high availability. The majority of businesses use Kafka for a variety of purposes, but its service-oriented architecture, which is independent of programming languages and extends its usability, is its strongest feature. Integration with Python is one of the Kafka use cases (Important in our case). Currently running Python-based programs can talk to one another using the Kafka message queue.
Apache Airflow
A workflow manager to schedule, orchestrate & monitor workflows. According to its definition, it is “A platform by Airbnb to programmatically author, schedule, and monitor data pipelines.” It streamlines increasingly complex enterprise procedures and is based on the idea of “Configuration as a code.” Directed acyclic graphs (DAG) are used by Airflow to control workflow orchestration. It enables data engineers to put together and control workflows made up of many data sources.
Apache Spark
An analytics engine for unstructured and semi-structured data that has a wide range of use cases. It supports a wide range of applications, including stream processing and machine learning, thanks to its straightforward and expressive programming style.
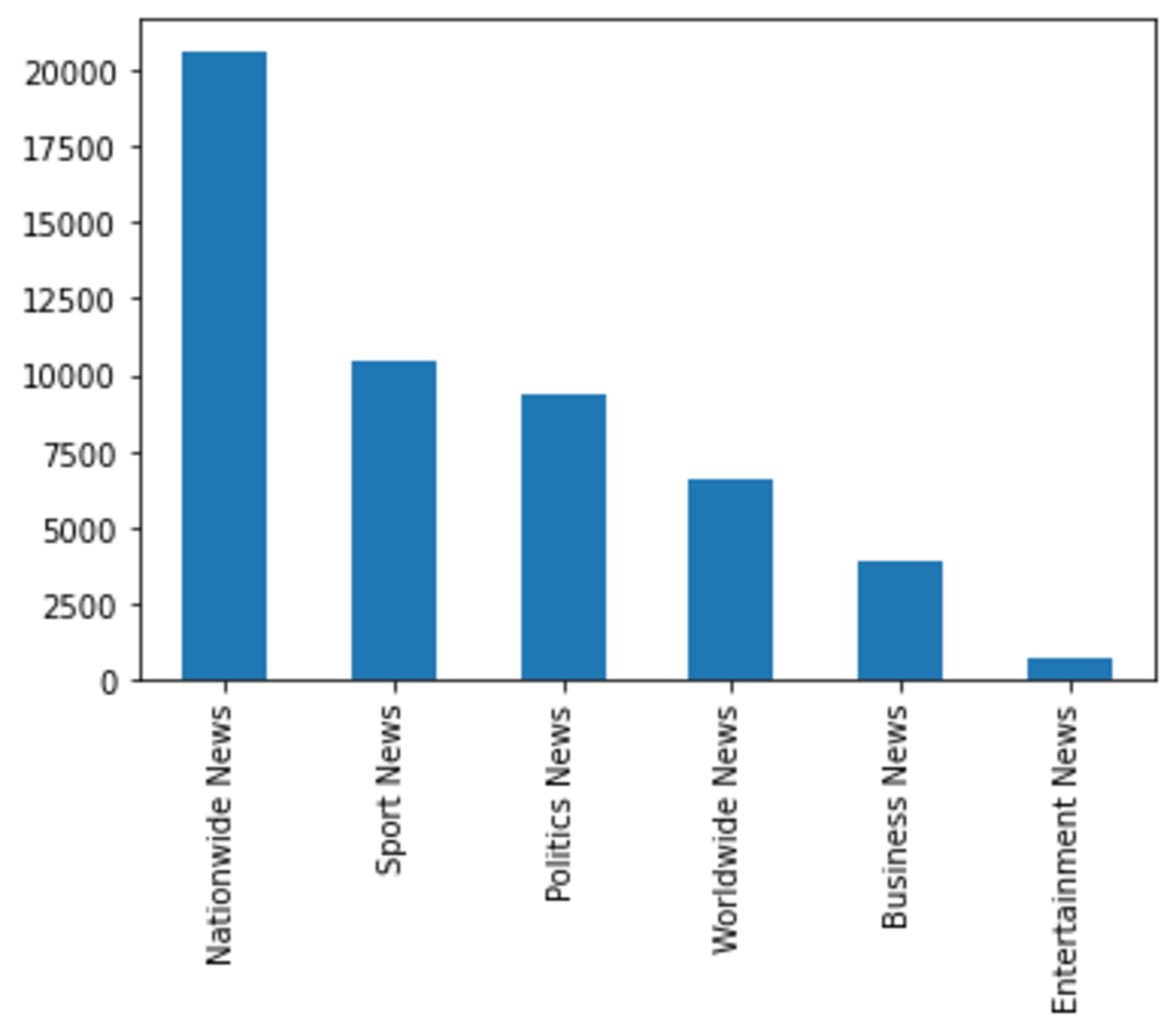
Data
For this project, we have a containing Amharic news text classification with baseline performance. The data contains articles that have a large number of words. So we did simple preprocessing to split those articles into sentences and ensure the spacing between the words are correct. Here are some of the insights of the data:
Approach and Setup
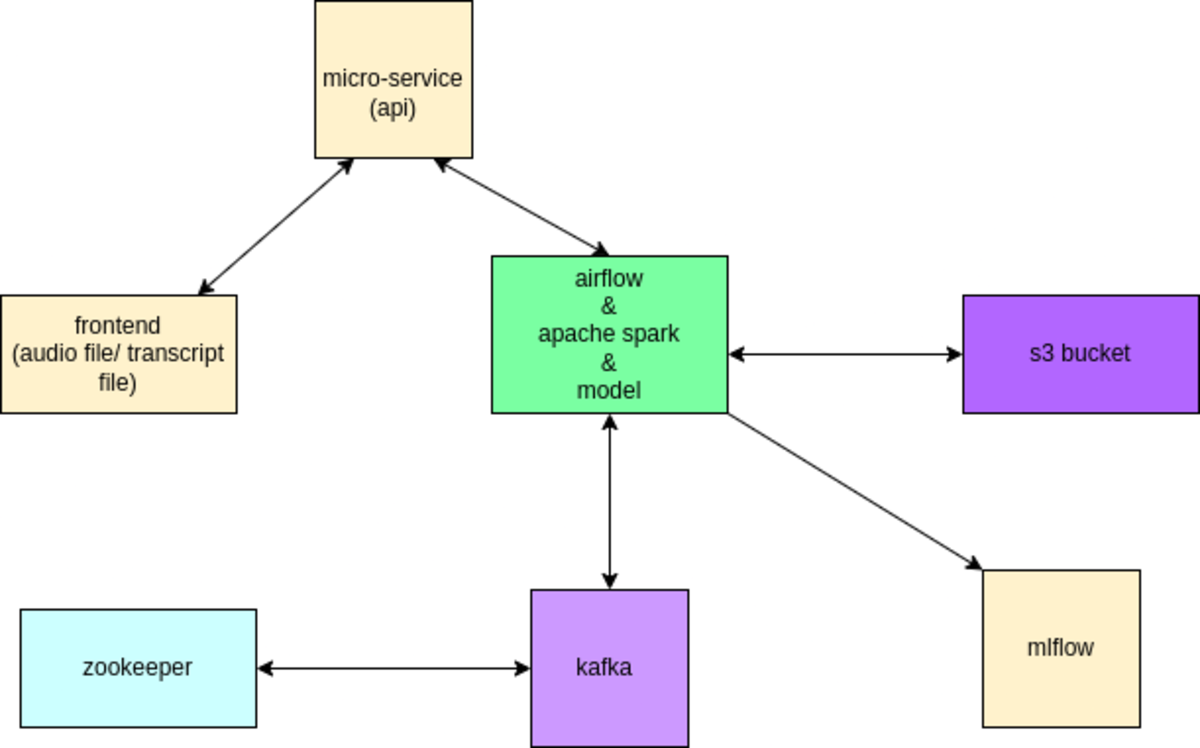
As we can see, we have some main components on the diagram. This include
Frontend - created with Reactjs, is how we interact with users to upload an audio file or validate audio file submissions. Backend (microservice API) - Django will be used to build the backend (microservice API), which will make it easier to facilitate communication between the frontend and Kafka for a seamless connection. Airflow - Airflow’s duty is to orchestrate messages of Kafka while also starting the transformation and loading of data onto Spark. Spark - Spark will be utilized to convert and load the data as we standardize it to ensure consistency and dependability. Kafka cluster - This will be the brain of the entire system as it facilitates the production of messages (ex. Audio files) on a topic to publishing it to the consumers.
Implementation of the Project
The project implementation can be explained with steps.
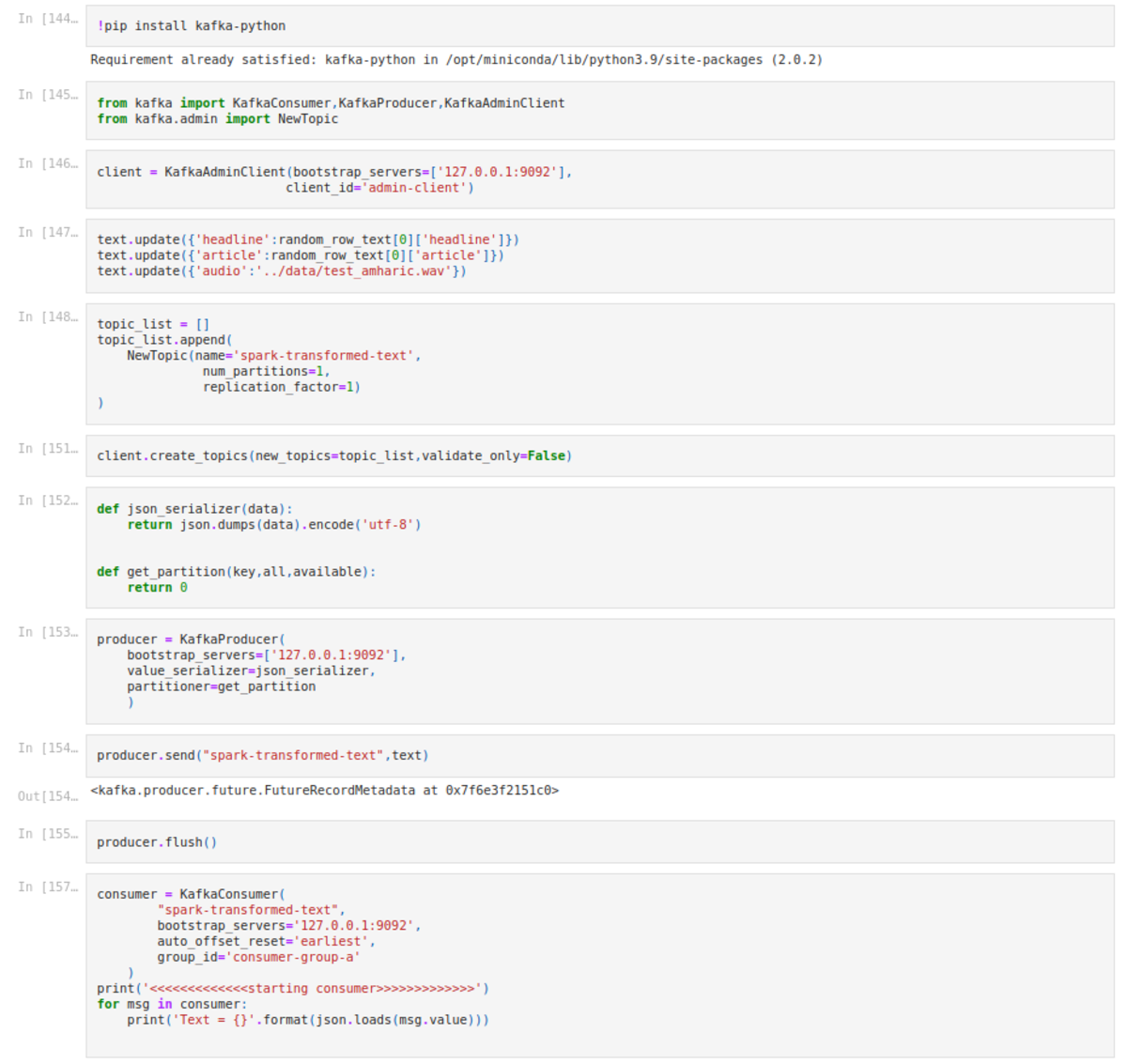
- Generating text randomly from the preprocessed dataset - First, we need to connect the spark session to a Kafka cluster. We used Pyspark to generate the random text from the preprocessed dataset.
- Stream the data - Here we use the Kafka cluster, to stream the generated data into the frontend for the user to see. we will send and publish the random text data, keeping in mind that we had uniquely generated the UUID and we configure this with the Django API, therefore there shall be no overlaps with the data, so once we have received it.
- Record or upload audio - Here, we will view the generated text on the front end and the user will read the text, record himself/herself, and then upload the audio file back to the back end. At this stage, we will place the file inside the S3 bucket, And the Airflow starts the preprocessing and validation of the data
- Preprocessing of the input audio - So once we have received the audio file we begin to carefully scrutinize it and clean it and pass it through. some checks include
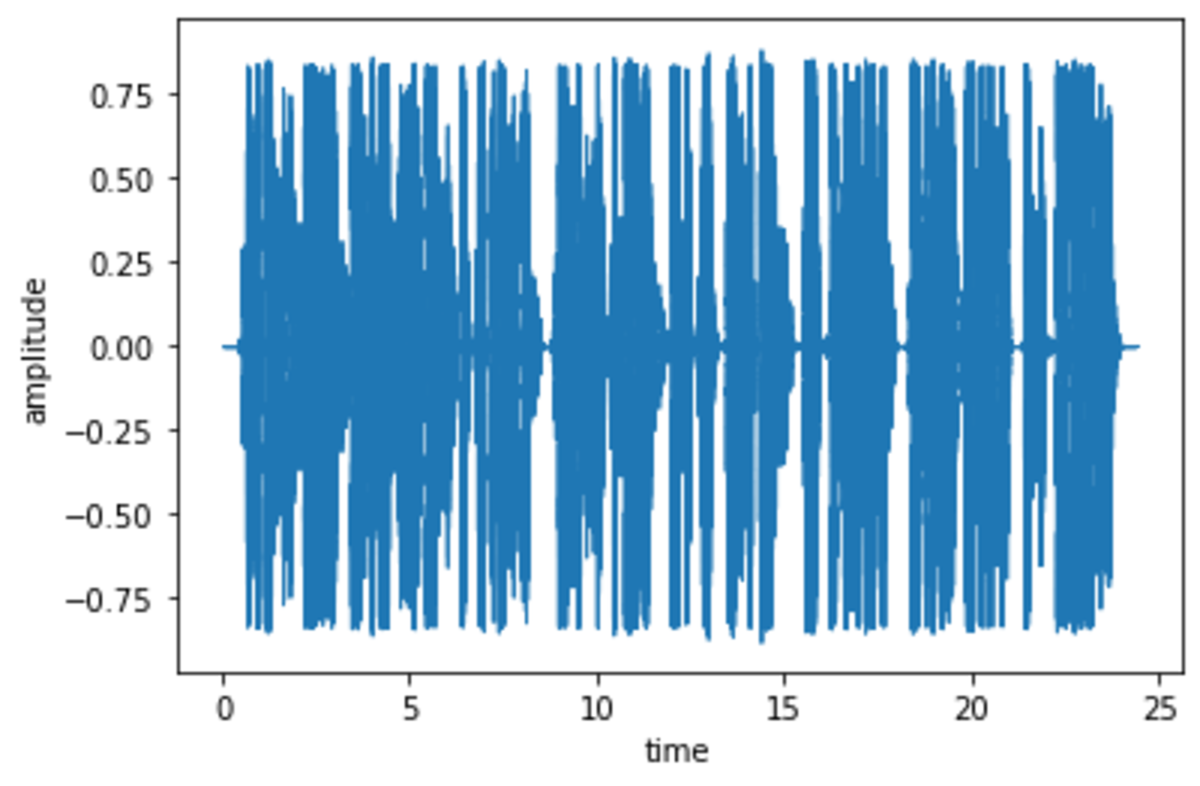
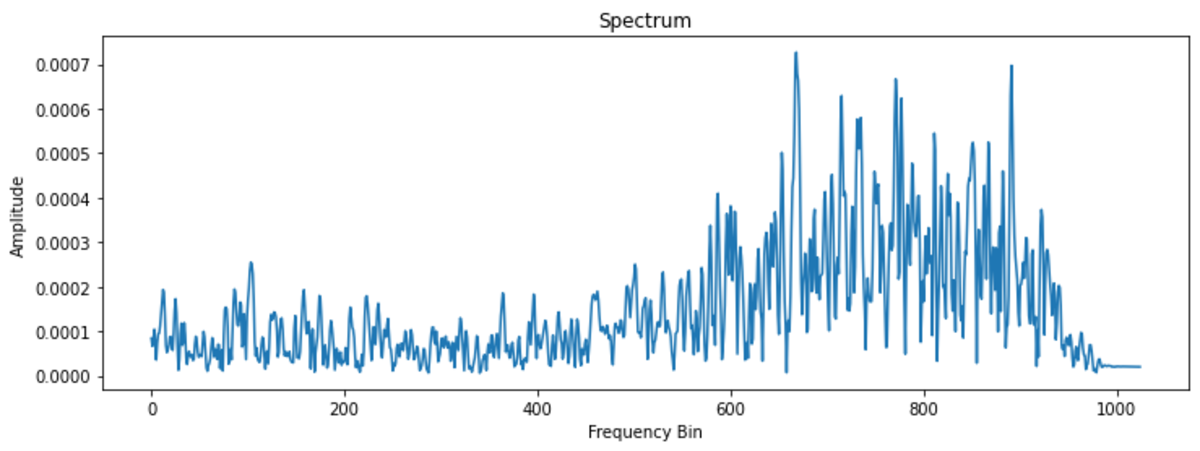
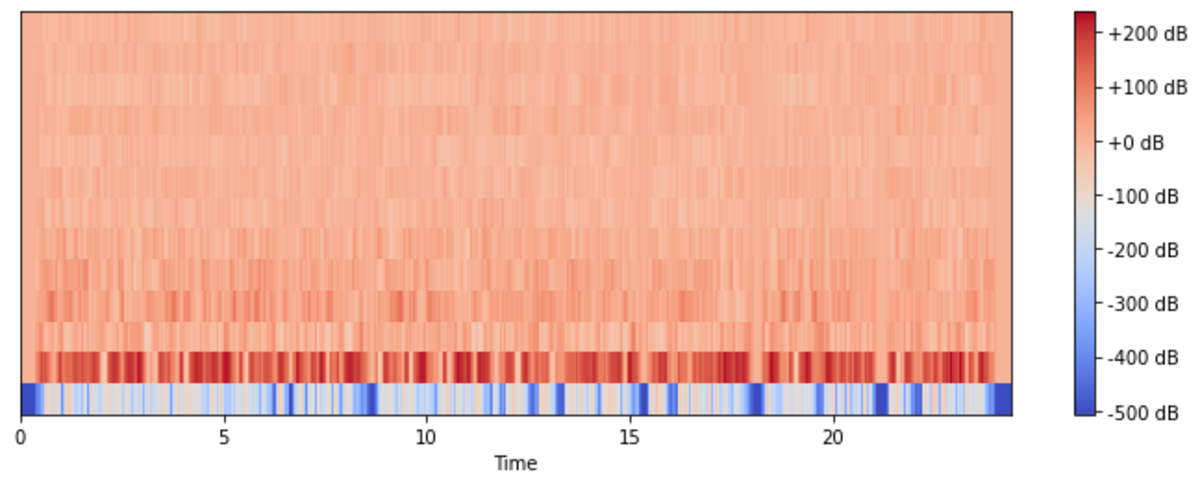
we check the audio file first of all whether it has data by displaying a simple waveform we check the frequencies of the audio file to see if they are normal we convert it into a spectrogram and check the mfccs, to see whether the standard 12 coefficients, if they are having some pattern.
- Validating the input audio - Validating at this stage can be done in many ways but for this projects we will keep it easy and check for silences and count the words count. we do that by spliting the audio file into chunks, that is words and then we store it and count the number of chunks whether they are similar to the length of the articles string split.
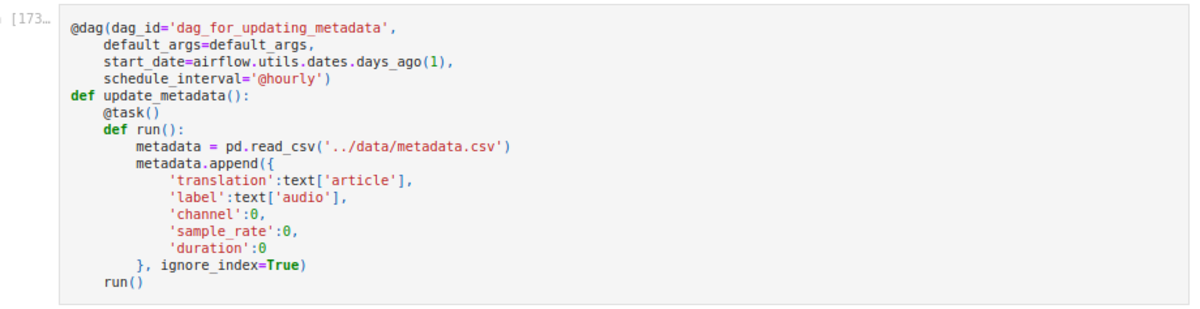
- Transforming and Storing into s3 bucket - Here we use the preprocessed audio data, if it passes the validation successfully then we will store the audio file by matching with the text id and update our metadata. Everything here have been done using spark.
- Scheduling Retraining of the Model - At this point we have got the collected and validated quality audios available with their metadata. So what we need now to complete the project is retrain the model using the new audio files. This will be scheduled using Airflow.
Lessons Learned
In this project, I have learned how to use Kafka, Airflow, and Spark together to yield a better result. Even though Spark was not necessary for our project, it has been a great addition to know how it connects with other tools because as the data gets bigger, the use of tools like Spark will become necessary. I have learned how to interact with each toll using Python and how this would make it easier in the future as our data increases.
Future Works
Due to time constraints, we could not finish everything we wanted to do on this project. So in the future, we want to include
- Add A Validation topic and use it to validate the audio file generated with another user
- Complete Retraining of a Speech-to-text Model to see improvement with Airflow schedule (has been implemented but improvement needed)
Amharic STT Data Collection
This content is accurate and true to the best of the author’s knowledge and is not meant to substitute for formal and individualized advice from a qualified professional.